
The Difference Between Com vs Net – Which Domain Extension should you use? Choosing the best domain extension for your business can be a difficult decision. There are so many options to choose from, and it is hard to know ...
Yahoo Answers is an internet-based community-powered knowledge marketplace, or Knowledge community, from Yahoo! Answers which enables users to post questions for others to answer and then vote on the ones they think are the most important. It is similar to ...

What is Yandex? Description: Yandex search is a popular search engine. It is owned by Yandex, a Russian search engine company. According to Liveinternet, in January of 2021, Yandex made over 51.2 percent of all the search traffic on Russian ...

Social bookmarking sites Traffic gurus joke that site visitors from social bookmarking sites is like an invasion – the crowds pour in and in a day or two they’re gone. Unfortunately this is true – after your itemizing rolls from ...

A Weebly Background Image Size A Weebly Background Image Size Checker is a useful tool for checking how large your selected images are. It works with a simple click of your mouse button. To use it, just select the images ...
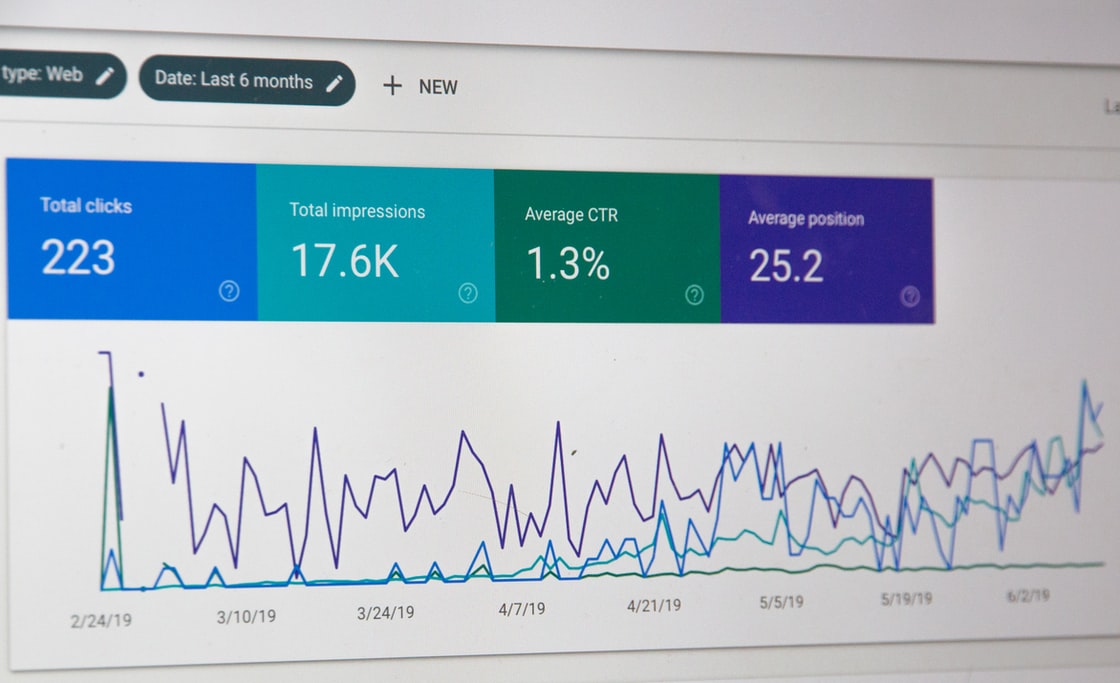
Filters cannot perform what action on collected data? Filters cannot perform on collected data that include shopping preferences. Include data from specific subdomains Convert dynamic page URLs to readable text strings Exclude traffic from particular IP addresses Include shopping preferences Correct ...

What feature is required to collect the number of comments users posted to a web page? Custom Metric is required to collect the number of comments users posted to a web page. Custom Dimension Calculated Metric Custom Channel Groupings Custom Metric ...
Which best describes the relationship between maximum cost-per-click (CPC) bids and Ad Rank? Which best describes the relationship between maximum cost-per-click (CPC) bids and Ad Rank? An increased CPC bid leads directly to a small increase in Ad Rank. CPC ...

An advertiser wants to know if Shopping ads will appear on YouTube. What should you tell her? An advertiser wants to know if Shopping ads will appear on YouTube. What should you tell her? Shopping Ads can only appear on ...

How Much Should a Website Cost in 2021? The next question that is going to be arising from this article is; “How Much Should a Website Cost in 2021?”. Well, this will have a direct bearing on the revenue generated ...